
线段树是最好的算法!
1. 基本线段树
P2471 [SCOI2007] 降雨量
先对数据离散化。记录相邻数据之间的年份差值(即 $\Delta y$),以及最大值的出现次数。
对于 false,最大值大于当前数或者等于的条件下数量多于 $1$,且年份差值与离散化后下标差值相等。
对于 true,最大值为当前数且数量为 $1$,且年份差值与离散化后下标差值相等。
对于 maybe,最大值为当前数且数量为 $1$,且年份差值与离散化后下标差值不等。
妈的,这道题真傻逼,讲的什么东西不清不楚的。
P5677 [GZOI2017] 配对统计
对于每个数 $a_i$,与其匹配的所有 $y$ 是确定的,且仅有 $1$ 或 $2$ 个。同样的,$a_i$ 作为 $y$ 的次数也是确定的,仅有 $1$ 或者 $2$ 次。可以进行一次排序求出。
考虑扫描线。加入新的点 $i$ 的贡献是:存在 $l<i$,有好对 $(l,i)$ 或者 $(i,l)$。然后这道题就做完了。
P5482 [JLOI2011] 不等式组
每次新增不等式相当于对值域区间加 $1$ 操作。
具体来说,对于新增一次不等式 $ax+b>c$:
- 若 $a>0$,对 $(\dfrac{c-b}a,+\infty)$ 进行 $+1$ 操作。
- 若 $a<0$,对 $(-\infty,\dfrac{c-b}{a})$ 进行 $+1$ 操作。
对于删减,改成 $-1$ 操作即可。
这就是区间修改单点查询,用树状数组维护查分数组即可。
P3792 由乃与大母神原型和偶像崇拜
维护区间最大最小值以及数量,和数量最大值。然后查询就是 $r-l$ 是否与 $max-min$ 相等,且数量最大值不超过 $1$。
P8476 「GLR-R3」惊蛰
把 DP 拍到线段树上,牛牛题!
考虑 dp 式 $f_{i,V}=\min\limits f_{i-1,j}$
空间复杂度的分析
假设维护的区间总长 $n=2^k$,这也就是说最后一层的节点个数为 $\sum\limits_{i=0}^k 2^i=2^{k+1}-1$。粗略来说,也就是有 $2n$ 个节点。然而,并非所有区间总长均为 $2$ 的正整数次幂,若 $2^k\le n< 2^{k+1}$,设 $f(x)$ 为区间长为 $x$ 的线段树的节点个数,则必然有 $f(2^k)\le f(x)<f(2^{k+1})$,因此只需要开 $2f(2^k)=2(2^{k+1})=4\times 2^k$ 大小的线段树即可。这就是通常「四倍大小」原因所在。
复杂度分析的线段树
一些简单题
P4145 上帝造题的七分钟 2 / 花神游历各国
发现每个数至多进行 $6$ 次开方运算后就会变成 $1$。那么考虑暴力修改,至多会修改每个点 $6(n+Q)$ 次,实际上远远小于这个数。因此维护区间最值即可。
CF438D The Child and Sequence
取模操作可以类似的看。每次取模会使数据范围缩小到 $<P$ 内。
尝试构造一种取模方式,使得一个数取模次数最多,也就是使一个数每次减小值最小,设 $x$ 取模次数为 $f(x)$。
显然,当 $x>y$ 时,必然有 $f(x)\ge f(y)$。当 $P>\dfrac {x}2$ 时,$\Delta x<\dfrac x2$;当 $P\le\dfrac x2$ 时,$\Delta x<P\ge\dfrac x2$。也就是说,$x$ 至多被取模 $\log x$ 次就会变成 $1$。
于是可以维护区间最值,当 $P$ 比这个最值小的时候才进行操作。均摊下来,复杂度是 $(n+m)\log V$。
ABC426F Clearance
给出 $n$ 个数 $a_i$,$q$ 次查询,对于 $i\in[l,r]$,使 $a_i\gets \max(0,a_i-k)$。并返回改变的和。
设 $[l,r]$ 内没被删空的数量为 $cnt_{l,r}$,不妨在询问前假设 $cnt_{l,r}$ 个物品都是可选 $k$ 个,进行区间减操作。然后减后 $a_i\le 0$ 的数,减掉多余贡献,就做完了。
具体来说,我们维护一棵带懒标记的线段树,可以维护 $cnt$ 以及区间最小值。先对区间整体做一次减 $k$ 操作。然后每次找最前面的 $\le 0$ 的 $a_i$,对其进行单点修改操作(即把 $cnt_{i,i}\gets 0$),并调整贡献,这可以直接线段树二分做到。
考虑整体的时间复杂度,每个位置至多被删空 $1$ 次,单点修改区间减操作是 $\mathcal O(\log n)$ 的,因此总复杂度为 $\mathcal O\left((n+q)\log n\right)$。
珂朵莉树(Old Driver Tree)
由李欣隆(nzhtl1477)于CodeForces Round #449 中发明,是一种基于 随机数据 的均摊复杂度的一种技巧,通常用于处理 颜色段均摊(区间推平操作) 问题的一种方法,而非数据结构。
基本元素
珂朵莉树基本操作都使用 set 进行,对于每个点都记录三个信息:l r v。表示这段值均为 $v$ 的区间 $[l,r]$。下面是结构体定义。
|
|
基本操作
split(pos) 分裂操作
即将原本 $[l,r]$ 的区间分裂成 $[l,pos)$ 以及 $[pos,r]$ 两段区间。返回后一区间的指针。
|
|
assign(l,r,v) 推平操作
将区间 $[l,r]$ 统一赋值为 $v$,这一操作与复杂度息息相关。
|
|
值得注意的是,这里必须先以 $r+1$ 分裂,再以 $l$ 分裂。假若先分裂 $l$,那么若 $r+1$ 在 $l$ 的分裂后的区间内,$l$ 会被删掉。
自定义操作
跟着下面的板子做就行。
|
|
例题
CF896C Willem, Chtholly and Seniorious
维护一个数据结构,支持以下操作:
1 l r x:对 $[l,r]$ 的所有 $a_i$ 加 $x$。2 l r x:对 $[l,r]$ 的所有 $a_i$ 赋值为 $x$。3 l r x:输出 $[l,r]$ 区间内第 $x$ 小的数。4 l r x y:输出 $\sum\limits_{i=l}^r a_i^x\bmod y$ 的值。数据完全随机。
我们只需要按照操作模板,写出区间加、区间 $k$ 小、幂求和即可。
|
|
用 set 实现的复杂度为 $\mathcal O(n\log\log n)$,用链表实现的复杂度为 $\mathcal O(n\log n)$。具体的证明见 hqztrue - 珂朵莉树的复杂度分析
。
2. 可持久化线段树
2.0 前置芝士
动态开点线段树
如果像传统线段树一样,对于左右儿子节点采取 $2x$ 与 $2x+1$ 的方案,那么可能导致节点过多,或者难以存储。这时「动态开点」的方法就会起作用。
顾名思义,这棵线段树可以做到「动态」。每个节点并非固定好,而是在访问到这个节点时才会「新建」。具体而言,我们维护一个 $now$ 用于表示最后一个节点的编号,对于新节点赋值为 $now+1$ 即可。并用 $ls$ 与 $rs$ 来记录每个节点的左右儿子。下面用区间加为例。
|
|
2.1 可持久化
可持久化线段树实际上是众多可持久化数据结构中的一种,却也恰恰是最经典的一个。其保留了所有历史版本信息,可方便的在历史版本上查询信息。
对于新版本的信息,我们对已有的部分不作新建,只对被影响到的部分进行「更新」操作。此操作不会影响历史信息,只会在新的版本的信息中进行修改操作。
下面的一张图(From OI-Wiki),很好解释了“可持久化”的原理。
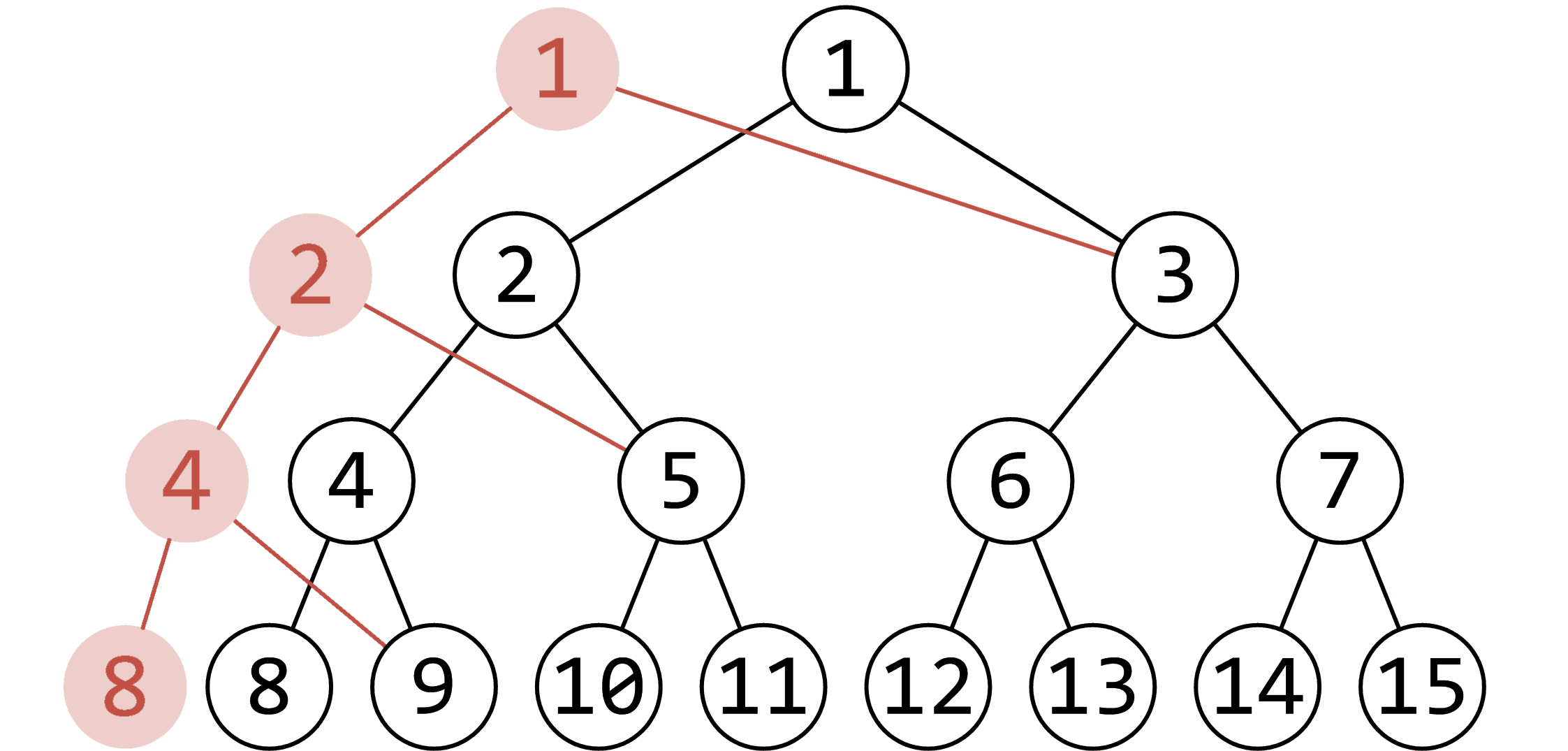
这相当于在单点修改的线段树中,修改八号结点后的历史版本,新增个数是 $\log n$ 级别。可持久化的线段树,实则上就是维护一个多版本的数组。
2.2 应用
2.2.1 主席树(可持久化权值线段树)
发明人是黄嘉泰,所以叫主席树。
一个著名的应用是区间 $k$ 小,详见下面一道模板题。
P3834 【模板】可持久化线段树 2
给出序列,多次查询
l r,求 $\max\limits _{i\in[l,r]}a_i$。
我们把每个下标当作新的版本,在值域上建线段树。
查询时做一步减法,用 $r$ 的版本减掉 $l-1$ 的版本,下面给出几个操作的写法。
- 建树(初始版本)
|
|
- 更新操作(新版本)
|
|
其中的 o 是当前版本的新根,x 为上一版本的根。
- 查询操作
|
|
这里的 o1 就是 $l-1$ 版本,o2 为 $r$ 版本。这和线段树二分很像。
2.2.2 树上主席树
序列上的版本是元素的前驱,树上的版本是其父节点。见下面一道例题。
P3302 [SDOI2013] 森林
维护一个森林,$Q$ 次操作,每次操作可以连接任意两棵树,这个操作是永久的;也可以查询 $x\to y$ 路径上第 $k$ 小的值。强制在线。
先对每一棵树建主席树。对于修改操作,用启发式合并,将节点更少的那棵树暴力修改,根据启发式合并理论,这一操作是 $\mathcal O(\log n)$ 的。然后就做完了。
2.3 更多可持久化数据结构
2.3.1 可持久化数组
可能算是对「可持久化线段树」最直接的应用了!
P3919 【模板】可持久化线段树 1(可持久化数组)
维护一个长度为 $n$,拥有多个版本的数组
都会写主席树了,这还不会写吗?
先对原序列建线段树,维护的内容就是单点对应版本值。然后对于修改操作,就对于新版本的树,先继承上一版本的节点,再新建对应自己位置的节点,这一部分会新建 $\mathcal O(\log n)$ 个节点。上文中的图很好解释了这种行为。
2.3.2 可持久化并查集
就是对 $fa_u$ 可持久化。我们平常写的均摊 $\mathcal O(n\alpha)$ 的路径压缩并查集显然在多个版本的情况下会 T 飞,所以考虑「按秩合并」这种操作严格 $\mathcal O(\log n)$ 的方法。
前面已经提到,可持久化线段树实际上维护的就是多版本的数组。可持久化并查集就是建立在此基础之上,用可持久化线段树进行维护。下面见模板。
P3402 【模板】可持久化并查集
给定 $n$ 个集合,第 $i$ 个集合内初始状态下只有一个数,为 $i$。
有 $m$ 次操作。操作分为 $3$ 种:
1 a b合并 $a,b$ 所在集合;2 k回到第 $k$ 次操作(执行三种操作中的任意一种都记为一次操作)之后的状态,保证已经进行过至少 $k$ 次操作(不算本次操作),特别的,若 $k=0$,则表示回到初始状态;3 a b询问 $a,b$ 是否属于同一集合,如果是则输出 $1$,否则输出 $0$。
前文已经说过,我们需要用「按秩合并」的方法对并查集进行维护,因为这样可以做到严格的 $\mathcal O(\log n)$ 复杂度的操作。
我们这里采用以深度为秩,将深度更小的树接在更大的树上。考虑复杂度:
不妨设 $dep_u\ge dep_v$,若不等则 $v$ 接在 $u$ 上深度必然不超过 $dep_u$。若取等则深度自增一位。按照如此方案,考虑最劣的二叉树,第 $i$ 层最多放 $2^{i-1}$ 节点,因此树高至多为 $\log n$,也就是说 find 函数是严格 $\mathcal O(\log n)$ 的。
接下来考虑可持久化部分。我们对每个版本都要有不同的数据结构维护,线段树很好地满足了这一性质。对于一个合并操作 u v,假设 $dep_u\ge dep_v$,那么相较于上一版本,更改的是 $dep_u$(若深度相等)以及 $fa_v$。特别的,若 $dep_u$ 被修改,我们需要新建节点。这是由于我们新建的版本只有 $v$ 是新的,其他都是上一版本的。新建节点后才能正确维护深度大小。
复杂度为 $\mathcal O(n\log^2n)$。
2.3.3 可持久化 Trie
P4735 最大异或和
给定一个非负整数序列 ${a}$,初始长度为 $N$。
有 $M$ 个操作,有以下两种操作类型:
A x:添加操作,表示在序列末尾添加一个数 $x$,序列的长度 $N$ 加 $1$。Q l r x:询问操作,你需要找到一个位置 $p$,满足 $l \le p \le r$,使得:$a[p] \oplus a[p+1] \oplus … \oplus a[N] \oplus x$ 最大,输出最大值。
设 $s_i=\bigoplus\limits_{j=1}^i a_i$,那么询问就转换成 $s_{p-1}\oplus(x\oplus s_n)$ 的最大值,后面一坨可以看作常量。
类比主席树的做法,我们传入 $r-1$ 版本以及 $l-2$ 版本(因为取值为 $p-1$),做一步差,即可计算这些版本是否有对应位置了。
|
|
3. 线段树合并与线段树分裂
3.1 「合并」
其实和「可持久化」操作十分相似。
顾名思义,线段树合并就是在对于多棵线段树上对相关信息进行合并的操作。显然,合并的两棵树的范围必然是相同的(也就是说这两棵线段树维护对应节点的区间以及信息是完全相同的)。另外,通常使用「动态开点」的线段树进行合并。因为若使用传统式的线段树,会增加许多冗余信息,导致内存爆炸。
实际上,我们通常对「权值线段树」上进行合并操作。下面见几个合并的例子。
3.1.1 一些「合并」的例子
连通块 $k$ 大值
给出 $n$ 个点,点有点权,$q$ 次查询。每次查询可以连接两个点,也可以查询一个点所在连通块内第 $k$ 小的数。
看到第 $k$ 小,自然想到建权值线段树。这里的「连接」操作,实际上就是对两个点所在连通块进行「合并」。我们将两者的权值线段树上,维护的对应值出现次数直接相加,就实现了「合并」操作。
连通块数颜色
给出 $n$ 个点,点有颜色,$q$ 次查询。每次查询可以连接两个点,也可以查询一个点所在连通块内的颜色个数。
有很多做法啊,但我们就按「合并」的思路说一下。每连接两个点,相当于将两个连通块的线段树的颜色进行或运算,只要存在颜色 $k$,就把其所在叶子结点设为 $1$。对于一段区间 $[l,r]$ 维护区间和即可。
下文的例题会见到更多「合并」操作。
3.1.2 「合并」的两种方法
3.1.3 复杂度分析
假设我们合并的是 $n$ 个不同点的线段树,那么对于一个点 $u$,使用「动态开点」的方法,空间上会建立 $\log n$ 个节点。因此空间复杂度是可以达到 $\mathcal O(n\log n)$ 的。
现在考虑时间复杂度。假设当前要合并大小为 $\lvert T_1\rvert$ 与 $\lvert T_2\rvert$ 的树,那么需要遍历的就是 $\mathcal O(\lvert T_1\rvert+\lvert T_2\rvert-\lvert T_1+T_2\rvert)$。则总时间复杂度为 $\mathcal O(\sum \lvert T_i\rvert-\lvert\sum T_i\rvert)<\mathcal O(m\log n)$,这里 $m$ 是操作次数。
所以线段树合并的复杂度为 $\mathcal O(m\log n)$。