
串串是诗,这是诗和远方!
1. 字符串 Hash
1.1 多项式 Hash
1.1.1 定义
多项式 Hash 是字符串 Hash 的基础。具体而言,对于 $a_0,a_1\cdots a_n$,以及固定整数 $b$、模数 $p$,其 Hash 值为:
$$\sum\limits_{i=1}^n a_ib^{n-i}\bmod p$$
对于字符串而言,每个元素 $a_i$ 相当于字符串的字符 $s_i$。
1.1.2 基础操作
查询子串 $[l,r]$ 的 Hash。只需预处理每个前缀的 Hash,设 $h_i=\sum\limits_{j\in[1,i]}a_jb^{n-j}\bmod p$ 表示 $[1,i]$ 的 Hash 值。
对于区间 $[l,r]$,其 Hash 值即为 $(h_r-h_{l-1}\cdot b^{r-l+1}) \bmod p$。
同样的, 字符串 Hash 亦可完成拼接操作。对于字符串 $s_1,s_2$,Hash 值分别为 $h_1,h_2$。那么二者拼接的 Hash 值就为 $(h_1b^{\vert s_2\vert}+h_2)\bmod p$。
|
|
1.2 性质
字符串 Hash 实际上是字符串到整数的映射。我们期望的情况下,我们有的字符串集会和数集形成一一映射,但是显然不尽人意。
对于 Hash 值不同的两个字符串, 二者一定不同。而对于具有相同 Hash 值的两个字符串,二者不一定相同。对于具有相同 Hash 值但不相同的两个字符串,叫做「哈希碰撞」。但在不碰撞的情况下,可以实现许多优秀的算法。
1.3 碰撞概率与双模 Hash
1.3.1 双模 Hash
双模 Hash 很简单,就是再取一对 $p$ 和 $b$ 计算。
1.3.2 碰撞概率
大体上说,假设有 $10^5$ 个不同字符串,我们要求每个字符串的 Hash 互不相同,也就是 $\approx 10^{10}$ 对关系。在 $\bmod p$ 意义下,总共有 $p$ 种不同 Hash 值。假设 $p=10^9+7$,那么就是约 $\dfrac{10^5}{10^9+7}\approx 10^{-4}$ 的概率有碰撞。
因此,引入双模 Hash 就可以大大减小碰撞的概率。
1.3.3 注意点
用 $2^{64}$ 作模数,即自然溢出,极有可能被卡。
大量 Hash、$10^7$ 次比较的 Hash 应该用双模。
模数可以常见质数,$b$ 取较大且随机。
1.3.4 卡 Hash
1.4 小应用
1.4.1 二分哈希
最长公共前缀:一种求 LCP 的小技巧,即把每一位的前缀 Hash 存下来,二分地找最靠后的前缀 Hash 相等的位置。
最长回文子串:存前缀与后缀 Hash,枚举每一位,把这一位当作回文串的中心。然后二分最长相等 Hash 段即可。
最长公共子串:假设 $m$ 个字符串的总长为 $n$,那么考虑二分长度。在 check 时我们只需对每一个长为 $k$ 的子串放在 Hash 内比较即可。
1.4.2 求最小循环周期
假设周期为 $k$,字符串长为 $n$。首先有 $k\mid n$。由于是周期,那么每 $k$ 位都是相等的。即 $S[1\dots k]=S[k+1\dots 2k]=\cdots=S[n-k+1\dots n]$。这个也就能推出 $S[1\dots n-k]=S[k+1\dots n]$,而且这是一个充要条件!
为什么呢,我们把左右两边按照 $k$ 为一段来分,那么 $S[1\dots k]=S[k+1\dots 2k]$,第二段相等为 $S[k+1\dots 2k]=S[2k+1\dots 3k]$。直到 $n$,就能退出上面那个条件了。这也就是 Hash 找字符串循环周期的线性做法。
1.4.3 例题
P3763 [TJOI2017] DNA
给出模式串与文本串,求文本串有多少个子串与模式串最多三位不同。
考虑枚举起始位,然后三次二分即可。
P3498 [POI 2010] KOR-Beads
直接枚举 $k$,然后枚举所有段,对于 $k$ 的段数为 $\left\lfloor \dfrac{n}{k}\right\rfloor$。
总复杂度即为 $\mathcal O(\sum\limits_{k=1}^n \left\lfloor\dfrac{n}{k}\right\rfloor)\approx\mathcal O(\sum\limits_{k=1}^n \dfrac{n}{k})\approx\mathcal O(n\ln n)$。
CF1063F String Journey
给定长度 $\le 3\times 10^5$ 的字符串 $s$,找到最大的 $k$,使得从前往后可以选出 $k$ 个不同子串 $t_1,\cdots,t_k$ 使得 $t_{i+1}$ 是 $t_i$ 的 真子串。
从后往前考虑,最后一位长度取 $1$ 必然最优。而若 $\vert t_{k-1} \vert> 2$,那么不如取 $\vert t_{k-1}\vert=2$ 更优。因此,从后往前第 $i$ 个子串,长度为 $i$ 最优。所以答案最大为 $\sqrt {2n}$。
根据这个性质,枚举每个答案 $k$。假设 $k=l+1$,设 $f_{l,i}$ 表示以 $i$ 为首个字符 $k=l$ 的后缀是否可行,在 dp 的过程中不断加入 $f_{l,k}=1$ 的串,然后到 $i$ 判断一下 $[i,i+l-1]$ 或者 $[i+1,i+l]$ 是否出现即可。
注意卡常。$\mathcal O(n\log n)$ 做法要二分 Hash,但没怎么想。
2. Manacher
一种在 $\mathcal O(n)$ 的时间内求最长回文串的算法。
2.1 回文串
对于串 $s$,若 $\forall i\in [1,\vert s\vert]$,都有 $s_i=s_{\vert s\vert -i+1}$,则 $s$ 为 回文串。
这实际上就是说 $s$ 是关于 $\dfrac {\vert s\vert+1}{2}$ 对称 的。对于奇回文串,其对称中心为中间的字符;对于偶回文串,$\dfrac{\vert s\vert+1}{2}$ 非整数,其对称中心为中间两数的间隙。
因此,奇回文串和偶回文串并不相同。而 Manacher 直接处理的是奇回文串。对于偶回文串,我们可以直接在所有间隙以及头尾间插入间隙字符,这样就可以转化奇回文串。为了统一二者,在奇回文串的空隙与两侧加上空隙字符,这样奇偶性不变,仍然是奇串。
假设回文中心为 $m$,若 $s[m-R+1\dots m+R-1]$ 这一子串是回文的,那么称 $R$ 是 $m$ 的一个 回文半径。 Manacher 所做的,就是找到每一个 $m$ 的 最长回文半径。
2.2 算法流程
朴素做法
对于每一个 $m$,枚举半径 $R$。这个很好做,但是 $\mathcal O(n^2)$ 的。
观察 & 优化
设 $R_i$ 表示以 $i$ 为对称中心的最长回文半径,$r$ 为已经计算的,最大的 $m+R_m-1$。
对 $i$ 进行分类讨论:
- $m<i\le r$:找到 $i$ 关于 $m$ 的对称点 $2m-i$,见下图,根据回文的性质,粉色段前部分与绿色段是对称的。因此,$R_i$ 的大小至少为 $\min(r-i+1,R_{2m-i})$。随后暴力拓展即可。
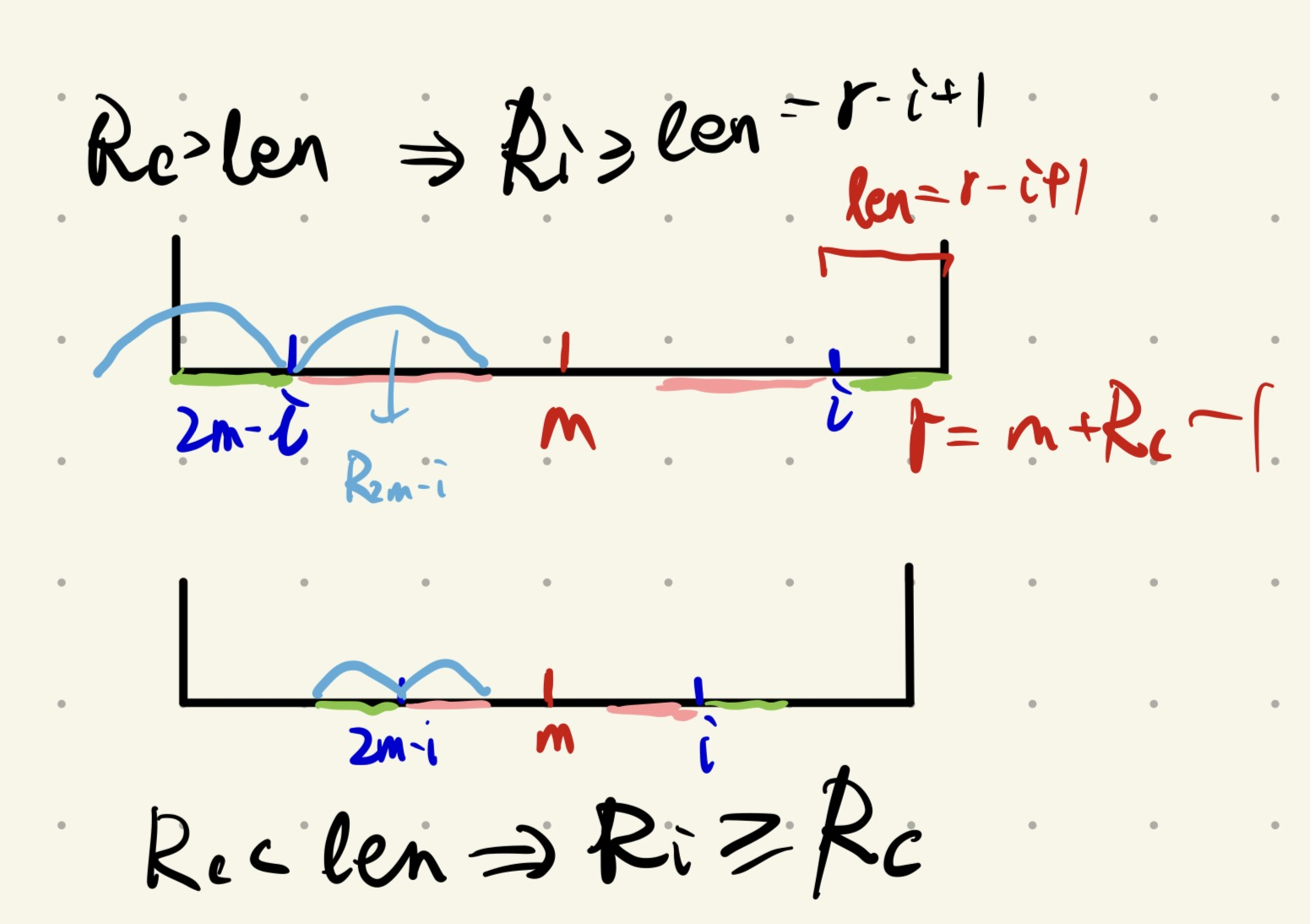
- $m>r$,那么无法借用先前已有的值,暴力拓展。
这样,就是 Manacher 的整个流程。
为什么时间复杂度是 $\mathcal O(n)$ 呢?
考虑当前的最大的 $r$,这个东西限制了第二个情况的复杂度是 $\mathcal O(n)$。
继续看第一个情况的暴力拓展,若 $R_{2m-i}<r-i+1$,那么 $R_i=R_{2m-i}$,看上面的第二张图,${2m-i}$ 的左侧已经无法匹配,因此对称地 $i+R_{2m-i}$ 的右侧也无法匹配。也就是说每一次暴力拓展必然会使 $r$ 增大。
综上可见,暴力拓展必然会使 $r$ 变大。而 $r$ 最大取到 $n$,所以复杂度是 $\mathcal O(n)$。
这个复杂度同时也证明了一个性质:一个长度为 $n$ 的串本质不同的回文子串数不超过 $n$。
2.3 例题
P3805 【模板】manacher
下面给出代码。
|
|
P4287 [SHOI2011] 双倍回文
求长度为 $4$ 的倍数,且有两个相同回文串拼接成的子串的最长长度。$n\le 5\times 10^5$。
由于一个串本质不同的回文子串个数只有 $\mathcal O(n)$ 个,求出来判断即可。
|
|
3. Border 与 前缀函数
Border
当一个串 $s$ 同时是 $T$ 的 真前缀 以及是 $T$ 的 真后缀 时,称 $s$ 为串 $T$ 的一个 border。
前缀函数
$\pi(i)$ 表示串 $T[0\dots i]$ 的最长 border 长度。
3.2 计算前缀函数
朴素算法
很显然的一个观察是,$\pi(i+1)\le \pi(i)+1$。对于 $\pi(i)$,只需从 $T[\pi (i-1)+1$] 位向前匹配。代码很容易写:
|
|
考虑字符串比较最多的次数,最优的情况是每次恰好就匹配,次数是 $n-1$。最劣情况下,会比较所有轮。总比较次数仍然是 $\mathcal O(n)$。因此总复杂度为 $\mathcal O(n^2)$。
小优化
注意一个结论:
- $S[1\dots i]$ 最长 border 长为 $\pi(i)$,次长 border 长度为 $\pi(\pi(i))$。第 $k$ 长 border 为嵌套 $k$ 层的 $\pi (i)$。这一点个人认为是比较显然的。假设最长 border 为 $k=\pi (i)$,存在比 $\pi(\pi (i))$ 长但比 $\pi(i)$ 短的 border,那么必然为 $S[1\dots k]$ 的前缀函数值,这个就是 $\pi(k)=\pi(\pi(i))$,矛盾。所以有这个结论。
根据这个结论,我们要计算 $\pi(i)$,我们只需不断地跳 $j=\pi(i-1)$,看下一位字符是否与 $S_i$ 匹配。匹配了就退出。
代码实现也十分简单,下面为以 $1$ 为首位的字符串。
|
|
复杂度为 $\mathcal O(n)$。这个其实可以势能分析的,但记住是这个复杂度就好。
3.3 KMP 以及其他应用
KMP
在一个文本串中找到模式串出现的所有位置。
一个很直观的做法,就是将模式串 $S$ 与文本串 $T$ 拼接:$S’=S+\mathbb{#}+T$。然后对 $S’$ 求前缀数组,每当 $\pi(i)=\vert S\vert$ 时就说明匹配成功。
另一个做法,其实和上面的做法大同小异。先求出模式串的前缀数组,然后维护一个 $p$ 表示文本串匹配到模式串的第 $p$ 位,然后仿照着前缀数组的做法做就好了。这一点其实就是对 $T$ 再求一遍前缀数组,不过前缀是 $S$。
周期
若 $p\in [1,\vert s\vert]$ 且 $\forall i\in[1,\vert s\vert-p],s_i=s_{i+p}$,则 $p$ 就是 $s$ 的一个周期。
很容易发现,假设 $\Pi$ 是 $s$ 的 border 集合,那么其对应着一个周期集合 $P$。$T$ 是一个长度为 $k$ 的 border $\iff$ $\vert s\vert -k$ 是 $s$ 的周期。
Weak Periodicity Lemma:若 $p$ 与 $q$ 都是 $s$ 的周期,且 $p+q\le \vert s\vert$,则 $\gcd (p,q)$ 也是 $s$ 的一个周期。
Periodicity Lemma:若 $p$ 与 $q$ 都是 $s$ 的周期,且 $p+q-\gcd (p,q)\le \vert s\vert$,则 $\gcd (p,q)$ 也是 $s$ 的一个周期。
失配树
由于 $\pi(i)<i$,考虑从 $\pi (i)$ 向 $i$ 连边。这样会构成一棵有根树,这棵有根树就是失配树。
失配树有良好的性质,从其构成看来,$u$ 的祖先就是他的一个 border。
P5829 【模板】失配树
求字符串前缀 $u,v$ 的最长公共 border。
就是 $u,v$ 在失配树上的 LCA。
3.4 exKMP/Z-Algorithm
和 KMP 没有关系,反而和 Manacher 很像。
3.4.1 定义与计算方法
定义一个字符串 $s$ 的 Z 函数 $z(i)=\vert\operatorname{lcp}(s,s[i\dots n])\vert$ 。即 $s$ 与 $s[i\dots n]$ 的最长公共前缀长度。称 $[i,i+z(i)-1]$ 为 $i$ 的 匹配段。算法流程中,记录 $r$ 最大的匹配段 $[l,r]$。对当前 $i$ 进行讨论:
- 若 $i\le r$,由于 $s[1,r-l+1]=s[l,r]$,因而 $s[i,r]=s[1+i-l,r-l+1]$。故 $z(i)\gets\min(z(i-l+1),r-i+1)$,然后暴力匹配。
- 若 $i>r$,直接暴力匹配。
这和 Manacher 几乎一模一样啊!
时间复杂度也是同样地分析,$\mathcal O(n)$,这里就不赘述了。
|
|
3.4.2 例题
P5410 【模板】扩展 KMP/exKMP(Z 函数)
第二个操作可以直接把 $a$ 接到 $b$ 后面,这里根据 Z 函数的性质算。和 KMP 的匹配是一样的。
|
|
P9576 「TAOI-2」Ciallo~(∠・ω< )⌒★
给定串 $s,t$,求有多少对四元组 $(l,r,l’,r’)$,使删掉 $s$ 的区间 $[l,r]$ 后,$s’[l’:r’]$ 是 $t$。
为了方便叙述,这里的 $l’,r’$ 映射到原字符串的相应位置上。
思考发现,可以将四元组分成两类:
- 当 $[l’,r’]\bigcap[l,r]=\varnothing$ 时,即选的 $[l’,r’]$ 就是原字符串的子串时。只需要找到所有与 $t$ 匹配的子串,这个贡献就是与子串无交的所有区间数。假设 $i$ 为匹配 $t$ 的左端点,那么贡献就是 $\dfrac {i(i-1)}2+\dfrac {[n-(i+m-1)][n-(i+m-1)+1]}{2}$。
- 当 $[l,r]\subseteq[l’,r’]$ 时,即 $[l’,r’]$ 是前后拼接后形成 $t$ 时。对于每个位置,维护与 $t$ 匹配的 LCP 以及 LCS(最长公共前/后缀)。若一对 $[l’,r’]$ 是合法的,设 $a_i=\operatorname{LCP}(T,S[i,n]),b_i=\operatorname{LCS}(T,S[1,i])$,则必然有 $a_{l’}+b_{r’}\ge\vert T\vert$ 且 $r’-l’\ge \vert T\vert$。会发现这满足了二维偏序的关系,于是用树状数组来维护。一对合法的 $[l’,r’]$,对答案的贡献就是 $a_{l’}+b_{r’}-\vert T\vert+1$。
![2][/img/string2.png]
这里详细说一下 Case 2 的做法。删除的区间一定不能有端点与 $l’,r’$ 之一重合,否则会出现和 Case 1 算重的情况。这个情况会在 $b_{r’}=m$ 的时候或者 $a_{l’}=m$ 出现,减掉即可。另一方面,我们在树状数组中存 $m-a_i$,并整体向右移一位,这样防止出现 $0$ 的情况。
|
|
4. AC 自动机
4.1 前置芝士
4.1.1 确定有限状态自动机(Deterministic Finite Automaton, DFA)
可以理解为,一个只接受 $\Sigma$ 集合元素的一个有向图。有若干个状态和一个起始状态,从前往后扫描每个字符,下一个状态仅由当前状态和当前字符决定。
4.1.2 Trie
4.2 算法流程
AC 自动机(Aho-Corasick Automaton, ACAM)是一个 基于 Trie 的结构,结合 KMP 建立的 DFA。实际上是 Trie 上的自动机。
4.2.1 $fail$ 的构造
考虑一个基础问题:给出文本串 $T$,以及 $n$ 个模式串 $s_1,\cdots,s_n$。求每个模式串在文本串上出现次数。
若 $n=1$,这就是普通的 KMP。我们维护的前缀数组记录了所有前缀的最长 border,对于任意 $i$,我们可以不超过 $\vert\Sigma\vert$ 次就找到其最长 border。
考虑对所有的模式串构建 Trie。类比上述做法,对于每个 Trie 上节点 $u$ 维护 $fail_u$,表示 所有模式串与 $u$ 后缀匹配的最长前缀 的节点编号。可以类比 KMP 的做法,维护 $fail_u$ 指针。假设已经维护了根节点到 $u$ 父节点的所有 $fail_u$,那么就跳到 $fail_{fa{u}}$ 上,检查有无 $s_u$ 这个子节点。有则令 $fail_u\gets son(fail{fa_u})$,无则继续跳 $fail_{fail_{fa_u}}$。显然,根据 border 理论,第一个找到的存在 $s_u$ 的节点就是 $fail_u$。这个“跳”的操作,实则上可以直接优化:对于每个没有 $v$ 子节点的节点 $u$,直接将 $v$ 设为 $fail_u$ 的 $v$ 子节点。这样向上继承,保证每个节点的转移都是 $\mathcal O(1)$,进而总复杂度 $\mathcal O(n\vert\Sigma\vert)$。
|
|
特别的是,当字符集很大时,这种复杂度可能无法满足要求。可以考虑 可持久化线段树 的优化(TBD)。
4.2.2 匹配
先把文本串塞到 Trie 里。在 Trie 遍历文本串时,不断跳 $fail_u$。经过的所有节点到根节点形成的串,都是文本串的一个子串。直接计数即可。
|
|
这个也很好卡,全为相同字符的模式串与文本串,这就退化到了 $\mathcal O(nm)$。
注意一个性质:$fail$ 指针形成的是一个 有向无环图,根据这个性质考虑优化。
4.2.3 匹配的优化
拓扑排序优化
在 Trie 上遍历文本串时,只对 $fail_u$ 进行计数 $num(fail_u)\gets num(fail_u)+1$,并不往上跳。然后对 $fail$ 构成的 DAG 跑拓扑排序。对于 $u$ 指向的点 $v$,$num(v)\gets num(v)+num(u)$。这样复杂度就降到 $\mathcal O(n+m)$。
|
|
dfs 优化
注意到每个点都只有一个出边,因此这构成一个 树形 结构,称为**「$fail$ 树」**。$fail$ 树的节点 $u$ 的子树,显然是包含 $rt\to u$ 这个串的集合。故可以树形 dp 优化,复杂度为 $\mathcal O(n+m)$,与拓扑优化异曲同工。
4.3 $fail$ 树
前面已经说过,$fail$ 指针的结构构成一棵树,具有机器良好的性质。
4.3.1 性质
- 是一棵 有根树。
- 对于树上节点 $u$,设根节点到 $u$ 构成的串为 $s(u)$。那么有 $ v\in\operatorname{subtree}(u)\iff s(u) \text{ is a suffix of } s(v)$。
根据性质 2,可以找到一个好用的结论:若 $s$ 为 $t$ 的子串,那么 $s$ 必然为 $t$ 某个前缀的后缀。
4.3.2 例题
4.4 AC 自动机上 DP
通常见于“存在子串”的一类最优化或者计数问题。
4.4.1 例题
P4052 [JSOI2007] 文本生成器
给出 $n$ 个模式串,求长度为 $m$ 的文本串使得存在至少一个模式串为其子串。$m\le 100,\vert s_i\vert\le 100,n\le60$
考虑补集转化,相当于求长度为 $m$ 的文本串不存在子串为模式串的个数。
设 $f(i,j)$ 表示长度为 $i$,以 Trie 树上 $i$ 节点为结尾的合法串数量。若 $j$ 与其子 $k$ 都合法,那么 $j$ 就可以转移到 $k$。关于合法性,实际上是在跳 fail 指针,$u$ 在 fail 树上到根节点上没有终止节点就是合法的。另外,Trie 上 $u$ 到根的链上点必须都是合法。
容易写出转移方程:$f(i+1,ch[j][k])\gets f(i+1,ch[j][k])+f(i,j)$。
注意最终根节点的贡献,实际上就是不以任何模式串前缀为后缀的贡献。
|
|
ABC419F All Included
给出 $n\le 8$ 个长度 $\le 10$ 的模式串 $s_i$,求长度为 $L\le100$ 的文本串,使所有模式串都在文本串内出现的文本串的数量。
设 $f(i,S,k)$ 表示填了前 $i$ 位,已经出现过的文本串集合为 $S$,当前在 Trie 树上的节点为 $k$ 的文本串数量。直接填下一位,即 $f(i+1,S\cup num_j,ch(k,j))\gets f(i,S,j)$,其中 $num_j$ 表示 Trie 上节点 $j$ 包含的模式串集合。
P2292 [HNOI2004] L 语言
给出 $n\le 20$ 个单词 $\vert s_i\vert\le2$0,$m$ 次询问,每次给出一个文本串 $\vert t\vert \le 2\times 10^6$,求 $t$ 最长前缀使前缀为单词组成。
每一次的询问显然无关。设 $f_i$ 表示 $t[1,i]$ 是否可以作为合法前缀,当 $f_i=1$,且 $t[i+1,j]\in S$ 时 $f_j=1$。考虑如何对 $t[i+1,j]\in S$ 进行刻画。
对于每个前缀,可以维护一个集合 $msk$,第 $i$ 位表示从第 $i$ 位的后缀是一个单词。在计算文本串 $t$ 是否合法的过程中,由于 $\vert s_i\vert \le 20$,故对于 $t$ 上的每一位只用看前 $20$ 位,直接遍历即可。
当然,这一步也可以压缩。设 $dp$ 表示前 20 位的 $f$ 值,位运算操作即可。
时间复杂度为 $\mathcal O(\sum\vert t\vert\cdot\vert s\vert)$。
|
|
CF696D Legen…
给出 $n\le 200$ 个模式串 $\vert s_i\vert\le200$,每个模式串有价值。定义一个文本串的价值为每个模式串出现次数与对应价值的乘积。构造长度为 $l\le10^{14}$ 的串,使价值最大。
设 $f_{i,j}$ 表示长度为 $i$,在 Trie 上节点为 $j$ 的最大价值,设 $val_{i}$ 表示以节点 $i$ 位后缀的单词价值之和。显然有 $f_{i+1,ch(j,k)}\gets \max f_{i,j}+val_{ch_{j,k}}$。其实这个 $val_{ch{j,k}}$ 也能写成 $val_{j,ch_{j,k}}$,那么转移式就是 $f_{i+1,ch(j,k)}\gets \max f_{i,j}+val_{j,ch_{j,k}}$,第一维直接扔掉。啊发现这不就是矩阵乘法的形式吗!
直接做就完了。
P3715 [BJOI2017] 魔法咒语
给出 $n$ 基本串以及 $m$ 个非法串。求由基本串构成的长度 $L$ 且子串不含非法串的串个数。
基本串长度之和 $\le 100$,非法串长度之和 $\le 100$。
将非法串也插入 Trie 中,并对末尾进行非法标记。
设 $f(i,j)$ 表示填完前 $i$ 个元素后,状态在 Trie 的 $j$ 节点上的方案数。边界条件显然更为严格,当 $ch(i,k)$ 为基本串在 Trie 上节点且不是非法串末尾时,转移 $f(i+1,ch(j,k))\gets f(i,j)$。
这个形式显然是可以直接矩阵优化的。
P5319 [BJOI2019] 奥术神杖
给定 $m$ 个模式串 $s_i$,有权值 $w_i$。有一个存在一些空位的长度 $n\le1501$ 的文本串,补全,使出现的模式串权值几何平均值最大(重复算多次)。模式串长度之和不超过 $1501$。
类比算术平均数的分数规划思想,几何平均数的最大化也可以用二分解决:
$$(\prod w_i)^{\frac 1k}\ge mid\iff \prod w_i \ge mid^k\iff\prod \dfrac {w_i}{mid} \ge 1$$
$$(\prod w_i)^{\frac 1k}\ge \exp(mid)\iff \dfrac 1k\cdot \sum \ln w_i \ge mid\iff\sum (\ln w_i-mid) \ge 0$$
相比之下,第二个取对数的精度更高,速度更快。(但我写的时候按照第一个写的,浮点乘法导致速度奇慢无比。因此,下面按照第一个来讲。)
然后就能 dp,设 $f(i,j)$ 表示已经填了前 $i$ 位,在 Trie 的 $j$ 号节点的最大值,有转移式:$f(i+1,ch(j,k))\gets val_{k}\times\max f(i,j)$,这里的 $val_k$ 表示以 $k$ 节点为后缀的单词的价值之积。每一次二分都重新 build 一下。
这道题输出的是方案,于是在 dp 的过程中记录一下方案即可。
时间复杂度 $\mathcal O(n\sum\vert s_i\vert\log V)$ 。
|
|